Step-by-Step Tutorial to Build a RAG Application with Brilliant AI


Introduction
Retrieval Augmented Generation (RAG) represents one of the most powerful applications of Large Language Models (LLMs) today. It addresses a fundamental challenge with LLMs: their tendency to hallucinate or generate incorrect information when they lack sufficient context. RAG solves this by grounding model responses in relevant source materials, significantly enhancing the accuracy and reliability of AI-powered applications.
RAG can work with various types of sources:
- Unstructured data: PDF documents, web pages, folders
- Structured data: Pandas DataFrames, CSV files
Some of the most impactful applications of RAG systems include:
- Customer service chatbots that answer questions based on website content and knowledge bases
- AI coding assistants that understand entire codebases to explain functionality and perform tasks
- Meeting assistants that transform discussions into actionable summaries
- Research assistants that condense lengthy articles into digestible summaries
Moreover, RAG plays a crucial role in AI agent workflows by providing the necessary context for accurate decision-making. As we move further into the era of generative AI, understanding how to build RAG applications has become an essential skill for developers.
This tutorial will guide you step-by-step through the process of building a RAG app that utilizes the Brilliant AI API for embeddings and chat, and Qdrant for vector storage. By the end, you'll have a working app capable of ingesting documents, storing vector embeddings, and interacting with users via multi-turn chat.
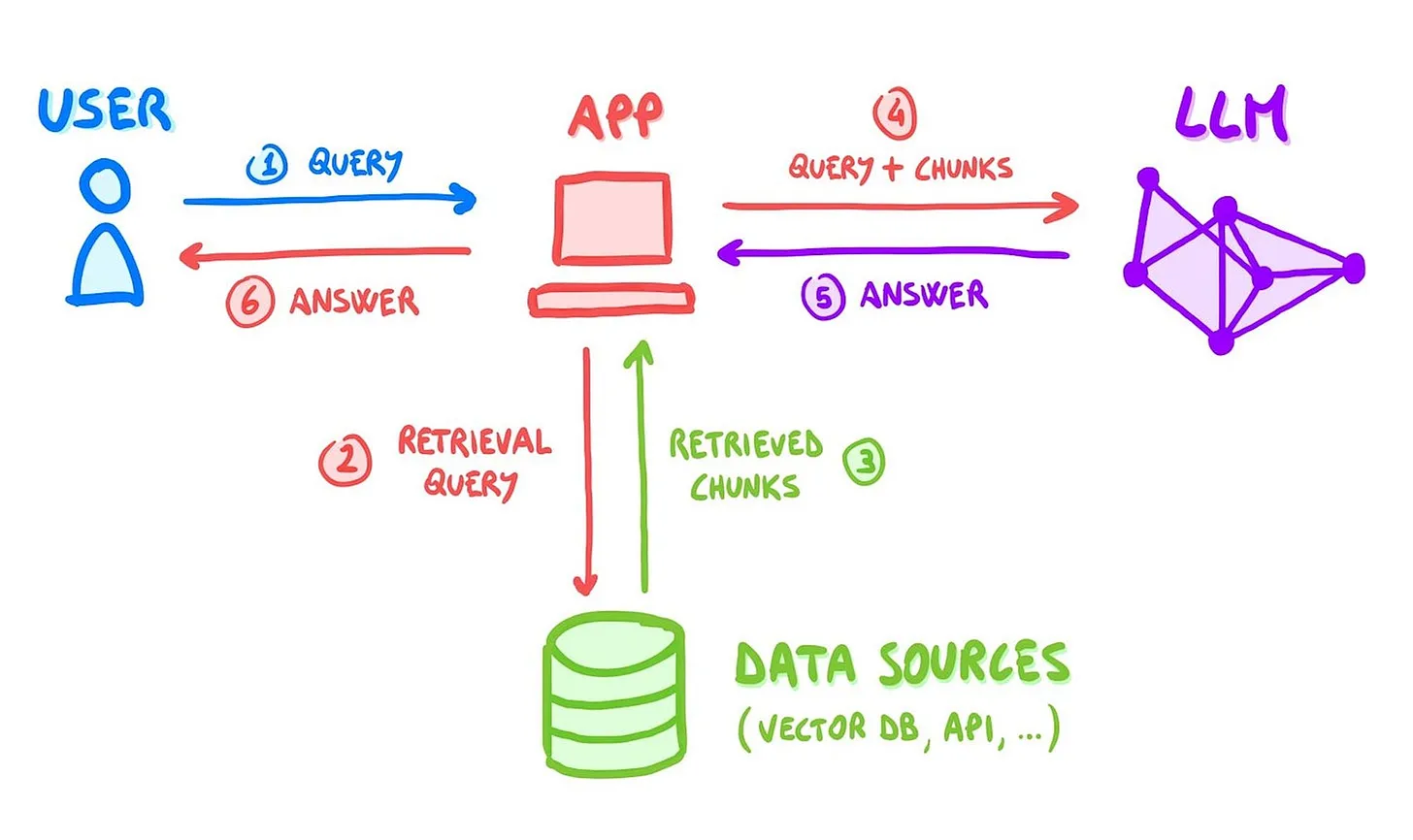
Overview of a basic RAG system. Source: Luca Rossi, Refactoring.fm
Key Terminology
Before we start coding, let's familiarize ourselves with some essential concepts:
- Embeddings: Numerical representations of words, phrases, or other data that capture their meaning in a way the model can understand.
- Vector store: A specialized database designed to store and retrieve data represented as vectors — numerical lists that capture the meaning or features of text, images, or other data types. In RAG systems, vector stores are used to efficiently find and compare embeddings.
- Collection: A collection in Qdrant is a named group of points (vectors with extra data) that can be searched.
- Chunking: The process of breaking large documents into smaller, manageable pieces that improve the accuracy of information retrieval, fit within the context limits of LLMs and optimize indexing and scalability.
Prerequisites
This tutorial assumes only basic Python knowledge, including understanding of:
- Variables and data types
- Functions
- Basic Python types
Required Libraries
We'll use the following libraries:
- OpenAI: For accessing Brilliant AI's API (which is OpenAI-compatible) for accessing the LLM and embedding model.
- Qdrant: An open-source vector database
- Streamlit: A Python framework for creating browser-based UIs
1. Project Setup
Directory structure
chat-with-pdf-project/
├── venv/
├── chat-with-pdf/
│ ├── app.py/
Create a chat-with-pdf-project folder and inside it create a virtual environment to install the necessary libraries and the chat-with-pdf folder to hold the script with your app logic.
-
Install Python 3.8 or later. Installation guide can be found here.
-
Environment Setup:
Create a virtual environment inchat-with-pdf-projectpython3 venv your_venv # Creates the virtual environment
source your_venv/bin/activate # Activates the virtual environment On Unix/MacOS
your_venv\Scripts\activate # Activates the virtual environment On Windows -
Install required libraries using:
pip install openai qdrant-client PyMuPDF beautifulsoup4 requestsNB: If the command doesn't work use
pip3. -
API Key:
Go to brilliantai.co/login
Obtain an API key:
- Set it as an environment variable:
Note: The active directory in your terminal should be
export BRILLIANTAI_API_KEY='your_api_key_here'chat-with-pdffolder when you export theAPI_KEY.
2. Import project dependencies
Import the following libraries in your app.py file:
import os
import uuid
import json
import requests
import fitz
import streamlit as st
from bs4 import BeautifulSoup
from urllib.parse import urlparse
from typing import List, Dict
from qdrant_client import QdrantClient
from qdrant_client.http.models import Distance, VectorParams, PointStruct
from openai import OpenAI
3. Helper Functions
These functions handle core utility tasks, such as reading files and data, preparing inputs, and processing outputs.
a. Read PDF Files
This function extracts text from a given PDF file. Each page is read sequentially, and all text is concatenated into a single string.
def read_pdf(file_path: str) -> str:
with open(file_path, 'rb') as file:
pdf_document = fitz.open(stream=file.read(), filetype="pdf")
text = ""
for page_num in range(pdf_document.page_count):
page = pdf_document.load_page(page_num)
text += page.get_text()
return text
Line-by-line analysis of the code
(Feel free to skip this if you already understand.)
-
def read_pdf(file_path: str) -> str:
Defines a function namedread_pdfthat accepts a single parameterfile_path, which is a string representing the path to a PDF file. It returns a string. -
with open(file_path, 'rb') as file:
Opens the file specified byfile_pathin binary read mode ('rb'). -
pdf_document = fitz.open(stream=file.read(), filetype="pdf")
Uses the PyMuPDF library (fitz) to open the file as a PDF document. -
text = ""
Initializes an empty stringtextto accumulate the extracted text from the PDF. -
for page_num in range(pdf_document.page_count):
Iterates over each page in the PDF document. -
page = pdf_document.load_page(page_num)
Loads the current page (page_num) from the PDF document as a Page object. -
text += page.get_text()
Extracts the text content from the current page using theget_text()method and appends it to thetextstring.
b. Chunk Text into Passages
This function splits large blocks of text into smaller, overlapping chunks for better processing in embeddings and search tasks.
def chunk_text_into_passages(text: str, chunk_size: int = 500, overlap: int = 100) -> List[str]:
chunks = []
start = 0
text_length = len(text)
while start < text_length:
end = min(start + chunk_size, text_length)
chunk = text[start:end]
chunks.append(chunk)
start += chunk_size - overlap
return chunks
Breakdown of the code
-
def chunk_text_into_passages(text: str, chunk_size: int = 500, overlap: int = 100) -> List[str]:
The function takes 3 arguments:text: A string that represents the input text to be chunked.chunk_size: An integer with a default value of 500.overlap: An integer with a default value of 100.
-
chunks = []
Initializes an empty listchunksto store the chunks of text created by the function. -
start = 0
Initializes a variablestartto 0, representing the starting index of the current chunk in the text. -
text_length = len(text)
Calculates the total length of the input text usinglen(). -
while start < text_length:
Starts a while loop that continues as long as thestartindex is less than the total length of the text. -
end = min(start + chunk_size, text_length)
Ensuresenddoes not exceed the total length of the text. -
chunk = text[start:end]
Extracts a substring (chunk) from the input text starting atstartand ending atend. -
chunks.append(chunk)
Appends the current chunk to thechunkslist. -
start += chunk_size - overlap
Updates thestartindex for the next chunk to ensure there is an overlap. -
return chunks
Once the loop finishes, the function returns the list containing all the text chunks.
4. Initialize Qdrant
Qdrant serves as the vector database to store and retrieve document embeddings. This code ensures the setup is ready.
if "qdrant_client" not in st.session_state:
st.session_state["qdrant_client"] = QdrantClient(url="http://127.0.0.1:6333")
qdrant_client = st.session_state["qdrant_client"]
collection_name = "rag_collection"
collections_info = qdrant_client.get_collections().collections
collection_names = [c.name for c in collections_info if c is not None]
if collection_name not in collection_names:
qdrant_client.create_collection(
collection_name=collection_name,
vectors_config=VectorParams(
size=1024,
distance=Distance.COSINE
)
)
Breakdown of the code
-
if "qdrant_client" not in st.session_state:
Checks if the key"qdrant_client"exists inst.session_state. -
st.session_state["qdrant_client"] = QdrantClient(url="http://127.0.0.1:6333")
If"qdrant_client"is not found, it initializes a newQdrantClientobject. -
collection_name = "rag_collection"
Defines the name of the Qdrant collection to be used. -
collections_info = qdrant_client.get_collections().collections
Retrieves the list of existing collections on the Qdrant server. -
collection_names = [c.name for c in collections_info if c is not None]
Creates a list of collection names from the retrievedcollections_info. -
if collection_name not in collection_names:
Checks if the collectioncollection_namealready exists. -
qdrant_client.create_collection(...
Creates a new collection on the Qdrant server if it doesn't already exist, specifying vector dimensions (size=1024) and distance metric (COSINE).
5. Document Processing and Embedding
a. Explanation of Key Concepts
An embedding is a numerical representation of text or other data generated by a large language model (LLM). It converts words, sentences, or even entire documents into vectors (arrays of numbers) that capture the semantic meaning of the input.
b. Process and Embed Documents
This function ingests data, chunks the text, generates embeddings, and upserts them into Qdrant.
def process_and_embed(
source: str,
embedding_client: OpenAI,
embedding_model: str = "snowflake-arctic-embed-l-v2.0"
) -> str:
if source.lower().endswith(".pdf"):
base_name = os.path.basename(source)
doc_id = os.path.splitext(base_name)[0]
text = read_pdf(source)
else:
raise ValueError("Source must be a PDF file path.")
chunks = chunk_text_into_passages(text)
embeddings = embedding_client.embeddings.create(
model=embedding_model,
input=chunks
)
points = [
PointStruct(
id=str(uuid.uuid4()),
vector=embed_data.embedding,
payload={"text": chunk_text, "doc_id": doc_id}
)
for chunk_text, embed_data in zip(chunks, embeddings.data)
]
qdrant_client.upsert(collection_name=collection_name, points=points)
return doc_id
Breakdown of the code
-
def process_and_embed(source: str, embedding_client: OpenAI, embedding_model: str = "snowflake-arctic-embed-l-v2.0") -> str:
Defines a function that takes three parameters and returns a string (doc_id). -
if source.lower().endswith(".pdf"):
Checks if the source ends with.pdf. -
base_name = os.path.basename(source)
Extracts the file name from the full file path. -
doc_id = os.path.splitext(base_name)[0]
Removes the file extension from the base name to getdoc_id. -
text = read_pdf(source)
Callsread_pdffunction to extract text from the PDF. -
chunks = chunk_text_into_passages(text)
Splits the extracted text into smaller chunks. -
embeddings = embedding_client.embeddings.create(...)
Generates embeddings for each text chunk. -
points = [PointStruct(... ) for chunk_text, embed_data in zip(chunks, embeddings.data)]
Creates a list ofPointStructobjects for each chunk-embedding pair. -
qdrant_client.upsert(collection_name=collection_name, points=points)
Inserts or updates vectors in the Qdrant collection. -
return doc_id
Returns the extracteddoc_id.
c. Retrieve Context
This function retrieves the most relevant content from Qdrant based on a query embedding.
def retrieve_context(query: str, embedding_client: OpenAI, top_k: int = 3) -> str:
embedding_model = "snowflake-arctic-embed-l-v2.0"
query_embed = embedding_client.embeddings.create(
model=embedding_model,
input=query
).data[0].embedding
results = qdrant_client.search(
collection_name=collection_name,
query_vector=query_embed,
limit=top_k
)
context_snippets = [res.payload["text"] for res in results]
return "\n\n".join(context_snippets)
Breakdown of the code
-
def retrieve_context(query: str, embedding_client: OpenAI, top_k: int = 3) -> str:
The function takes three parameters, including the number of top results to retrieve,top_k. -
embedding_model = "snowflake-arctic-embed-l-v2.0"
Sets the embedding model (provided by Brilliant AI). -
query_embed = embedding_client.embeddings.create(...).data[0].embedding
Generates the vector representation for the query text. -
results = qdrant_client.search(... limit=top_k)
Searches Qdrant for the most similar vectors. -
context_snippets = [res.payload["text"] for res in results]
Extracts the text from each search result's payload. -
return "\n\n".join(context_snippets)
Joins the retrieved text snippets into a single string.
6. Chatbot with Conversation History
Here, we define a Chatbot class to interact with the LLM. It allows users to choose a model, send prompts, and keeps track of conversation history—comprised of user inputs and model responses. The chatbot retrieves relevant context from a PDF document and combines it with the user's input to generate a response from the model.
a. Define the Chatbot Class
class Chatbot:
def __init__(self, model_name: str):
api_key = os.getenv("BRILLIANTAI_API_KEY")
if not api_key:
raise ValueError("Please set 'BRILLIANTAI_API_KEY' in environment variables.")
self.model_name = model_name
self.client = OpenAI(base_url="https://api.brilliantai.co", api_key=api_key)
self.conversation_history: List[Dict[str, str]] = []
def add_message(self, role: str, content: str):
self.conversation_history.append({"role": role, "content": content})
def chat(self, user_message: str) -> str:
context = retrieve_context(query=user_message, embedding_client=self.client, top_k=3)
context_message = (
"Relevant context to help answer the user's question:\n\n"
f"{context}\n\n"
"Provide a concise and direct answer without revealing the context to the user."
)
self.add_message("system", context_message)
self.add_message("user", user_message)
try:
response = self.client.chat.completions.create(
model=self.model_name,
messages=self.conversation_history,
temperature=0.7
)
assistant_message = response.choices[0].message.content
self.add_message("assistant", assistant_message)
return assistant_message
except Exception as e:
return "I'm sorry, I encountered an error."
Breakdown of the code
-
class Chatbot:
Defines aChatbotclass for managing interactions with the LLM. -
def __init__(self, model_name: str):
Initializes an instance of theChatbotclass with a specified AI model name. -
api_key = os.getenv("BRILLIANTAI_API_KEY")
Retrieves theBRILLIANTAI_API_KEYenvironment variable. -
if not api_key: raise ValueError(...)
Throws an error if theapi_keyis missing. -
self.model_name = model_name
Stores the model name (e.g., "gpt-4") in theself.model_nameattribute. -
self.client = OpenAI(base_url="https://api.brilliantai.co", api_key=api_key)
Initializes anOpenAIclient for making API requests. -
self.conversation_history: List[Dict[str, str]] = []
Initializes an empty list to track the conversation history. -
def add_message(self, role: str, content: str):
Defines a method to add a message to the conversation history. -
def chat(self, user_message: str) -> str:
Defines a method for handling a user's chat message and generating a response. -
context = retrieve_context(...)
Fetches relevant context based on the user's message. -
context_message = (... f"{context} ...")
Prepares a system message that includes the retrieved context. -
self.add_message("system", context_message)
Adds the context message to the conversation history. -
self.add_message("user", user_message)
Adds the user message to the conversation history. -
response = self.client.chat.completions.create(...)
Sends the conversation history to the Brilliant AI API to generate a response. -
assistant_message = response.choices[0].message.content
Extracts the assistant's response from the API output. -
self.add_message("assistant", assistant_message)
Stores the assistant's response in the conversation history. -
return assistant_message
Returns the assistant's response. -
except Exception as e:
Handles any exceptions that occur during the API call.
7. Build the Streamlit UI
The main function provides the entry point for our app. The app provides a user interface for uploading a PDF, selecting an LLM model, and interacting with it. Users can embed the uploaded document into a vector store, view statistics about the vector store, and engage in a multi-turn chat with the chatbot using the document as context. The function manages user inputs, handles document ingestion, and displays the chat history.
def main():
st.title("RAG Chat with PDF")
model_list = ["llama-3.3-70b", "mistral-nemo", "llama-3.2-8b"]
chosen_model = st.selectbox("Select a Model:", model_list)
if "chatbot" not in st.session_state:
st.session_state["chatbot"] = Chatbot(model_name=chosen_model)
if chosen_model != st.session_state["chatbot"].model_name:
st.session_state["chatbot"] = Chatbot(model_name=chosen_model)
embedding_client = st.session_state["chatbot"].client
uploaded_file = st.file_uploader("Upload a PDF to embed into the vector store", type=["pdf"])
if uploaded_file is not None:
temp_file_path = f"/tmp/{uploaded_file.name}"
with open(temp_file_path, "wb") as f:
f.write(uploaded_file.read())
st.success(f"Saved file to {temp_file_path}")
if st.button("Ingest Document"):
doc_id = process_and_embed(
source=temp_file_path,
embedding_client=embedding_client,
embedding_model="snowflake-arctic-embed-l-v2.0"
)
st.success(f"Document '{doc_id}' has been ingested into Qdrant.")
st.write("## Multi-turn Chat")
if "chat_history" not in st.session_state:
st.session_state["chat_history"] = []
user_input = st.text_input("Ask a question about the ingested document:")
if st.button("Send Message") and user_input.strip():
bot_response = st.session_state["chatbot"].chat(user_input)
st.session_state["chat_history"].append(("user", user_input))
st.session_state["chat_history"].append(("assistant", bot_response))
for role, content in st.session_state["chat_history"]:
if role == "user":
st.markdown(f"**You:** {content}")
else:
st.markdown(f"**Assistant:** {content}")
if __name__ == "__main__":
main()
Line-by-line breakdown
-
st.title("RAG Chat with PDF")
Sets the title of the Streamlit application. -
model_list = ["llama-3.3-70b", "mistral-nemo", "llama-3.2-8b"]
Creates a list of model names available for selection. -
chosen_model = st.selectbox("Select a Model:", model_list)
Displays a dropdown menu for users to select a model. -
if "chatbot" not in st.session_state: ...
Checks if a chatbot object exists in the Streamlit session state. -
if chosen_model != st.session_state["chatbot"].model_name: ...
Reinitializes the chatbot if the selected model has changed. -
embedding_client = st.session_state["chatbot"].client
Retrieves the embedding client from the current chatbot instance. -
uploaded_file = st.file_uploader(... type=["pdf"])
Allows the user to upload PDF files. -
if uploaded_file is not None: ...
Saves the uploaded file to a temporary path. -
if st.button("Ingest Document"):
Callsprocess_and_embedto insert the document into the vector database. -
st.write("## Multi-turn Chat")
A subheader indicating the chat section. -
if "chat_history" not in st.session_state: ...
Initializeschat_historyif it doesn't exist. -
user_input = st.text_input("Ask a question about the ingested document:")
Provides a text input box for the user. -
if st.button("Send Message") and user_input.strip(): ...
Sends the user's question to the chatbot and appends the response. -
for role, content in st.session_state["chat_history"]:
Displays the user and assistant messages in a formatted way.
Running the app
To run the app, use the command:
streamlit run app.py
Conclusion
Congratulations! You've built a complete RAG application capable of ingesting PDF documents, generating vector embeddings, and performing multi-turn chats using retrieved context. This provides a powerful foundation for creating AI-powered applications.
This app showcases the potential of retrieval-augmented generation in real-world applications, from document analysis to interactive learning. With this structure in place, you can extend the app further by adding more sophisticated document preprocessing, supporting additional file formats, or enhancing the UI for a better user experience.
Feel free to experiment with various parameters such as the temperature of the model (to control its creativity) or the top_k results from the embedding model (e.g., changing from 3 to 1) to see how the responses change.
1
Upserting in Qdrant is the process of adding new vectors or updating existing ones in a collection. If a vector with the same ID already exists, upserting replaces it with the new data. If the ID is new, the vector is simply added to the collection. This operation ensures that the collection stays updated with the latest data without requiring separate insert and update steps.